Before I started to work with Gesel on creating the No Boundaries Archive, I’d made websites using WordPress and Squarespace and Wix, but I’d never had the experience of building a digital archive. It’s taken some time to orient myself with respect to the digital archive’s more complex structure. This blog post, in which I’ll provide a diagram of the components of the No Boundaries Archive, is meant as a helpful jump start for others who might feel similarly disoriented. If that’s you, I want to first make it clear that digital archives are structured many different ways and built using many different kinds of software. This post is not meant to be prescriptive. This is just how we’ve gone about building ours.
We started by researching what kinds of software other performing arts organizations used for their digital archives and decided to build the No Boundaries Archive using the collection management software CollectiveAccess. We made the choice for several reasons. An important one was that we were looking to create interconnectivity between our digital archive and others. Because several other prominent dance and performance archives were already built using CollectiveAccess, we felt using the same software would make connections easier. That the software is open-source was another important criterion for two reasons: we wanted to build a digital archive structure that could, ultimately, be shared and adopted by others, and using open-source software was a priority of our main funder, the Digital Humanities Advancement program at the NEH.
Early in the process, we were fortunate to connect with Stephanie Neel, the lead archivist at Mark Morris Dance Group (MMDG). The MMDG archive was also using CollectiveAccess, and Stephanie generously offered to show us what their database looked like from the perspective of the person entering archival data. This was so helpful! If you want a similar experience (minus Stephanie’s expertise), there’s a CollectiveAccess user demo that you can explore for yourself (login is demo and password is demo). I recommend taking a look.
Now, back to my larger question of architecture…For the sake of clarity, and at the risk of sounding even more like an ad, here is a description of CollectiveAccess software from Whirl-I-Gig, its developer:
“The two main components of CollectiveAccess are Providence, the core cataloguing and data management application, and Pawtucket, an optional “front-end” publication and discovery platform. Providence provides a relational approach to cataloging that allows users to create and describe relationships between different record-types, and construct hierarchical relationships for complex collections, and to do so using commonly accepted library and archive standards…For publicly accessible collections, Pawtucket offers the web presentation tools that can bring an archive to light.”i
Gesel had started working with a web designer on a WordPress site for No Boundaries before we received funding to build the rest of the archive, and we wanted to use that WordPress site. This meant we wouldn’t need Pawtucket to build the outward facing website for the archive (although Pawtucket is made to do just that). We would need Pawtucket, however, to make a smooth visual transition between Gesel’s WordPress website and the database, which we were building using Providence. Below is a diagram of this structure.
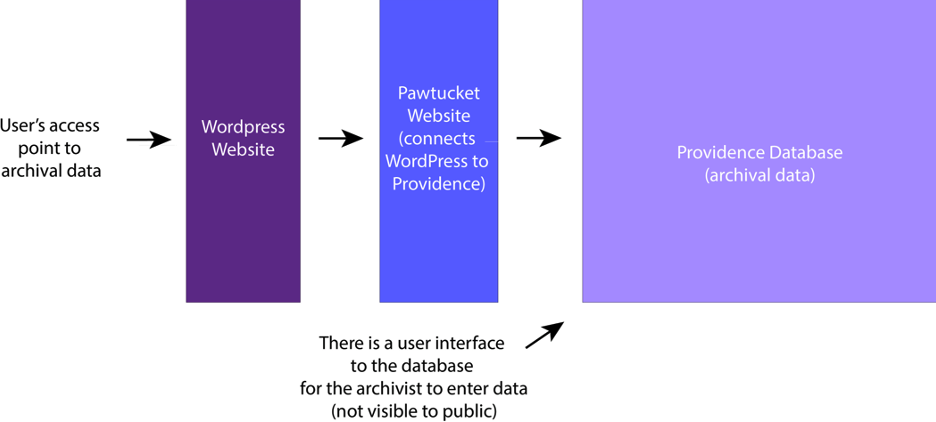
One part of this process that’s been challenging for me is a kind of horse-and-cart problem related to the interconnection between all the pieces in this digital organism. For example, the WordPress website needed to take shape in order finish the database – because the website designs showed how data needed to be presented to users. At the same time, the database needed to be built in order to complete the website, because without a working database it’s difficult to know exactly what features and connections it’s possible to manifest on the website.
This interconnection, while challenging, has kept my approach to the process of archive building both holistic and iterative – helping me climb the learning curve, and helping Gesel and me move closer to creating a meaningful digital framework for No Boundaries.
Published by